


.png)
Qu'est-ce que la science des données géospatiales ?

Michael Tuijp
Geospatial Data ScientistLa science des données est un mot à la mode. Elle est utilisée comme synonyme d'analyse des (grandes) données, d'apprentissage automatique, d'apprentissage profond et d'intelligence artificielle. En raison de l'utilisation généralisée de ce terme, il semble y avoir une certaine confusion sur ce qu'est réellement la science des données géospatiales (et sur ce qu'elle n'est pas). Dans une série de trois blogs que je publierai ces prochaines semaines, je ferai la lumière sur la terminologie et les possibilités de ce phénomène. Dans ce premier blog, je commence par le commencement : qu'est-ce que la science des données géospatiales ?
The Geospatial Data Science lifecycle
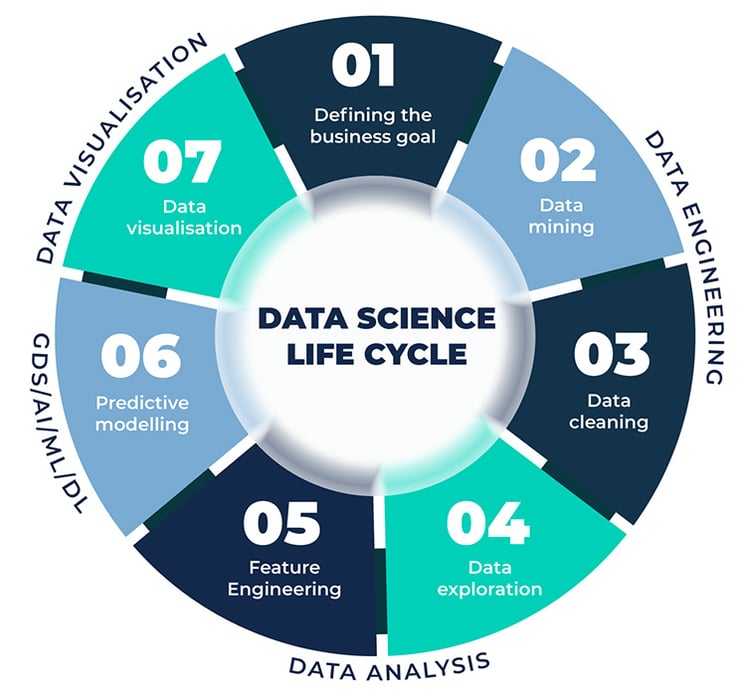
Un processus de science des données géospatiales (SDG) peut être décrit en sept étapes :
- Définir l'objectif de l'entreprise ;
- Exploration des données (ingénierie des données) ;
- Nettoyage des données (ingénierie des données) ;
- Exploration des données (analyse des données) ;
- Ingénierie des caractéristiques (analyse des données) ;
- Modélisation prédictive (GDS/AI/ML/DL) ;
- Visualisation des données.
Image 1 : les sept étapes de la science des données (géospatiales). Le texte se poursuit sous l'image.
ÉTAPE 1 : DÉFINIR L'OBJECTIF DE L'ENTREPRISE
La première étape est universelle pour tout projet impliquant des données. Définir l'objectif. Que voulez-vous savoir et pourquoi ? La science des données géospatiales n'est pas une fin en soi, mais un moyen de prendre des décisions fondées sur des données.
En tant que consultant, c'est là que je peux apporter une valeur ajoutée aux clients de Tensing. Il ne suffit pas de maîtriser l'aspect technique. En tant que force extérieure, je peux examiner votre organisation et vos objectifs avec un esprit ouvert. Je peux vous aider à séparer correctement les objectifs des ressources. En outre, il est souvent possible de faire beaucoup plus que ce que l'on pense.
ÉTAPES 2 ET 3 : INGÉNIERIE DES DONNÉES
L'ingénierie des données est la première étape technique de tous les processus liés aux données. La première étape de la phase d'ingénierie des données consiste à collecter les données nécessaires au projet spécifique. Il y a souvent beaucoup à faire pour obtenir les bonnes données à partir des bonnes sources et dans les bons formats. C'est pourquoi il convient d'examiner d'un œil très critique ce dont vous avez besoin et surtout ce dont vous n'avez pas besoin. L'efficacité du processus s'en trouvera grandement améliorée par la suite.
Après avoir compilé un ensemble de données approprié, il est temps de nettoyer les données. Dans la pratique, il manque toujours des valeurs, il existe des tableaux différents qui signifient la même chose et il y a souvent des incohérences.
Tensing utilise principalement FME (un outil ETL optimisé pour travailler avec des géodonnées) pour compléter la phase d'ingénierie des données. En tant que scientifique des données géospatiales, je peux compter sur 60 collègues certifiés qui sont entièrement spécialisés dans l'ingénierie des données géospatiales.
Image 2 : FME est le meilleur choix de logiciel dans le domaine de l'ingénierie des données géospatiales selon Tensing. Le texte se poursuit sous l'image.

ÉTAPES 4 ET 5 : ANALYSE DES DONNÉES
Après avoir terminé la phase d'ingénierie des données, il est temps de commencer à travailler avec les données. Sur la base d'hypothèses, vous vérifiez si vous pouvez extraire toutes les informations souhaitées de l'ensemble des données disponibles. Pour ce faire, vous pouvez utiliser des visualisations de test. Lorsque vous déterminez que votre sélection de données est complète, vous pouvez passer à l'étape suivante. Il arrive parfois que les étapes d'ingénierie des données doivent être affinées avant d'aller plus loin.
Au cours de l'étape d'ingénierie des caractéristiques, vous créez de nouvelles caractéristiques basées sur les données existantes. Il s'agit de valeurs pertinentes pour votre modèle, mais qui ne sont pas incluses en tant que variables distinctes. Prenons l'exemple de la marge brute : ventes - valeur d'achat. Si vous avez besoin de la marge brute en tant que caractéristique distincte pour générer votre modèle prédictif, incluez-la dans votre ensemble de données au cours de la phase d'ingénierie des caractéristiques.
Il est essentiel d'exécuter soigneusement les cinq premières étapes avant d'entamer la phase de modélisation prédictive. Tout d'abord, parce que vous serez confronté à de grandes listes d'erreurs. Deuxièmement, parce que le résultat sera considéré comme un "déchet" (garbage in, garbage out). Les informations issues de votre modèle sont susceptibles de présenter des valeurs extrêmes, d'être beaucoup trop positives (ou négatives) ou d'être tout simplement incompatibles avec la réalité.
ÉTAPE 6 : MODÉLISATION PRÉDICTIVE
La science des données est principalement associée à l'étape de la modélisation prédictive. Prédire les tendances sur la base des données passées (et présentes). L'intelligence artificielle, l'apprentissage automatique et l'apprentissage profond sont des outils qui permettent la modélisation prédictive. Dans un prochain blog, je développerai un exemple pratique : la maintenance prédictive. Gardez donc un œil sur nos canaux sociaux et notre site web !
La modélisation prédictive est impossible sans passer soigneusement par les étapes précédentes. Les données n'ont de valeur que si elles sont correctes à 100 %. Ce fait est une vérité absolue dans la pratique de la science des données.
ÉTAPE 7 : VISUALISATION DES DONNÉES
La visualisation des données est la raison pour laquelle vous faites (généralement) tout cela. Pour montrer certaines informations à un large éventail de parties prenantes de manière compréhensible, il existe un tableau de bord, une carte thermique ou une visualisation en 3D, selon ce qui convient le mieux à votre projet.
LA COMPOSANTE GÉOGRAPHIQUE
Le monde des systèmes d'information géographique s'est taillé une place à part. Travailler avec des données de localisation est un peu différent. Cela s'applique également à la science des données géospatiales. Le principal défi consiste à intégrer correctement des sources de données sans composante géographique avec des données géométriques. Une connaissance approfondie des données géographiques est absolument nécessaire pour créer des modèles prédictifs capables de vous dire non seulement ce qui va se passer, mais aussi où.
Vous avez besoin d'aide pour relever un défi dans le domaine de la science des données géospatiales ? N'hésitez pas à nous contacter !