


.png)
Flux de travail de Snowflake Databricks avec Snowflake

Michael Tuijp
Geospatial Data ScientistIl existe de nombreuses façons d'interroger les données. Comme nous l'avons expliqué dans notre article précédent " Connexions simples Snowflake-Python aux données BAG et à Snowpark ", nous avons utilisé Snowflake pour charger des données BAG depuis le Snowflake Marketplace directement dans un notebook Jupyter local. Mais que se passerait-il si vous pouviez exécuter la requête directement dans votre environnement Azure Cloud et l'exécuter automatiquement selon un calendrier de votre choix en un seul clic ? C'est possible avec Databricks ! Entrez dans Databricks !
QU'EST-CE QUE LE DATABRICKS ?
Databricks a été fondée pour offrir une alternative au système MapReduce et fournit une plateforme basée sur le nuage juste à temps pour les clients qui traitent des données volumineuses. Databricks a été créé pour aider les utilisateurs à intégrer les domaines de la science des données, de l'ingénierie et de l'entreprise dans le cycle de vie de l'apprentissage automatique. Cette intégration facilite les processus, de la préparation des données à l'expérimentation et au déploiement des applications d'apprentissage automatique.
Selon l'organisation à l'origine de databricks, la plateforme databrick est 100 fois plus rapide que la source ouverte Apache Spark. En unifiant le pipeline impliqué dans le développement d'outils d'apprentissage automatique, Databricks est censé faciliter le développement et l'innovation et accroître la sécurité. Les clusters de traitement de données peuvent être configurés et déployés en quelques clics. La plateforme comprend plusieurs fonctions de visualisation de données intégrées pour afficher les données sous forme de graphiques.
L'UTILISATION DES DATABRICKS
Une fois que vous avez démarré Databricks, allez dans l'onglet "Compute" dans la barre de gauche.
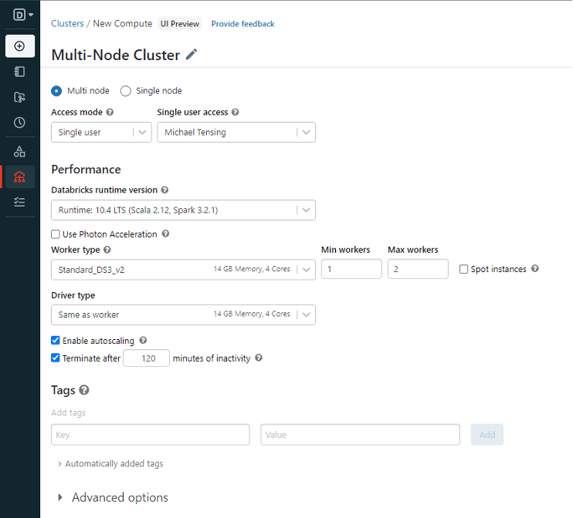
L'écran de configuration pour la création d'un cluster est assez simple. Par défaut, le cluster est configuré comme un "cluster multi-nœuds" qui, comme son nom l'indique, utilise plusieurs nœuds en parallèle. Cette configuration est utile pour les très grandes quantités de données.
Pour notre exemple, nous utilisons principalement les paramètres par défaut. La seule chose que vous pourriez vouloir modifier (en fonction de la puissance de calcul disponible dans votre organisation) est le nombre minimum et maximum de travailleurs requis.
L'utilisation du type de travailleur Standard_DS3_v2 avec un minimum de 1 travailleur et un maximum de 2 travailleurs devrait fournir suffisamment de mémoire pour notre exemple.
Voilà, c'est fait ! Vous êtes maintenant prêt à exécuter Python Notebook dans Databricks.
TÉLÉCHARGEZ VOTRE NOTEBOOK JUPYTER
Il est maintenant temps de charger notre Jupyter Notebook, le fichier .ipynb. Cliquez sur l'onglet 'New' et créez un nouveau notebook, puis cliquez sur l'onglet 'File'. A partir de là, cliquez sur 'Import Notebook' et naviguez jusqu'au fichier .ipynb que vous avez sauvegardé dans l'article précédent.
Voilà, vous avez téléchargé le carnet de notes dans Databricks ! La seule ligne de code à ajouter est celle ci-dessous. Puisque nous travaillons sur un cluster dans un Cloud, nous avons encore besoin d'installer les paquets nécessaires sur celui-ci.
!pip install snowflake.snowpark.python
Après avoir exécuté ce code, vous pouvez exécuter le reste du code exactement de la même manière que dans Jupyter Notebook. Vous obtiendrez exactement les mêmes résultats.
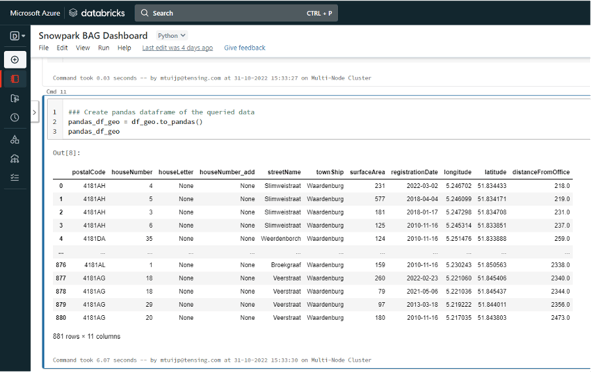
MISE EN PLACE D'UN CARNET DE NOTES DANS LE PIPELINE
Maintenant que nous avons produit les mêmes résultats que dans notre exemple de notebook Jupyter, allons plus loin. Puisque nous exécutons notre notebook avec Databricks, nous pouvons suivre quelques étapes très simples pour exécuter ce notebook périodiquement dans notre environnement Cloud sans intervention humaine.
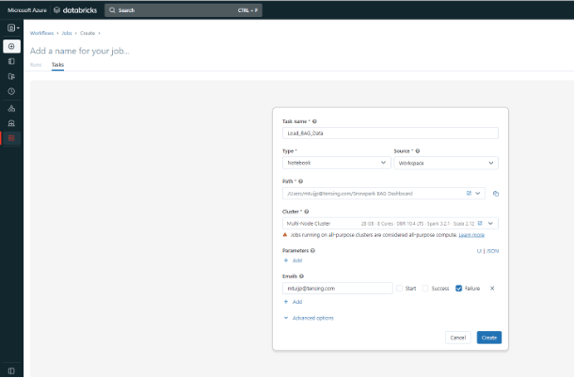
Dans la barre principale à gauche, allez à l'onglet inférieur 'Workflows'. A partir de là, cliquez sur 'Create Job' et vous verrez l'écran ci-dessous. Ici, entrez Notebook sous 'Type' et Workspace sous 'Source'. Ensuite, sélectionnez le chemin d'accès à votre carnet de notes et au cluster que nous venons de créer. En outre, vous pouvez utiliser certaines options avancées pour, par exemple, choisir d'envoyer un courriel à quelqu'un en cas d'échec.
Après avoir défini la tâche, vous pouvez également programmer l'exécution périodique de votre bloc-notes à un jour et une heure spécifiques. Après l'avoir créé, cliquez avec le bouton droit de la souris sur "Planifier", ce qui vous amène à l'écran ci-dessous. C'est ici que vous définissez exactement quand et à quelle fréquence vous voulez que le carnet s'exécute.
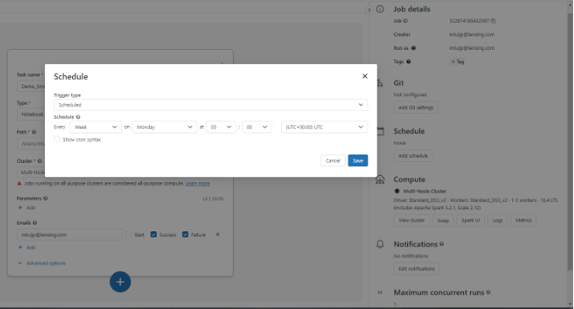
Félicitations ! Non seulement vous avez créé un notebook dans Databricks qui se connecte à un jeu de données BAG public dans Snowflake, mais vous avez également mis en place un flux de travail automatique pour exécuter le notebook à des intervalles de temps spécifiques. Ce qui nécessitait auparavant un certain nombre d'opérations complexes se fait désormais en quelques clics !
Si vous souhaitez en savoir plus sur les applications possibles de ce type, contactez-nous. Nous nous ferons un plaisir de vous aider !