


.png)
Eenvoudige Snowflake Databricks workflow met Snowflake

Michael Tuijp
Geospatial Data ScientistEr bestaan veel manieren om data in te laden. Zoals we in ons vorige artikel ‘Eenvoudige Snowflake-Python connecties met BAG data en Snowpark’ uitlegden, hebben we Snowflake gebruikt om BAG-gegevens van de Snowflake Marketplace rechtstreeks in een lokaal Jupyter-notebook in te laden. Maar wat als je de query rechtstreeks in je Azure Cloud-omgeving kunt uitvoeren en deze met één klik automatisch op een door jouw gekozen schema uit kan voeren? Dat is mogelijk met Databricks!
Wat is Databricks?
Databricks is opgericht om een alternatief te bieden voor het MapReduce-systeem en levert een just-in-time cloud-gebaseerd platform voor klanten die big data verwerken. Databricks werd opgericht om gebruikers te helpen de velden datawetenschap, engineering en het bedrijf erachter te integreren in de levenscyclus van machine learning. Deze integratie helpt de processen van datavoorbereiding tot experimenten en de inzet van machine learning-toepassingen te vergemakkelijken.
Volgens de organisatie achter databricks is het databrick-platform honderd keer sneller dan het open source Apache Spark. Door de pijplijn te verenigen die betrokken is bij de ontwikkeling van tools voor machine learning, zou Databricks de ontwikkeling en innovatie vesnellen en de veiligheid verhogen. Dataverwerkingsclusters kunnen met enkele klikken worden geconfigureerd en ingezet. Het platform bevat verschillende ingebouwde datavisualisatie functies om gegevens in grafieken weer te geven.
Het gebruik van databricks
Zodra je Databricks hebt opgestart, ga je naar het tabblad ‘Compute’ in de linkerbalk.
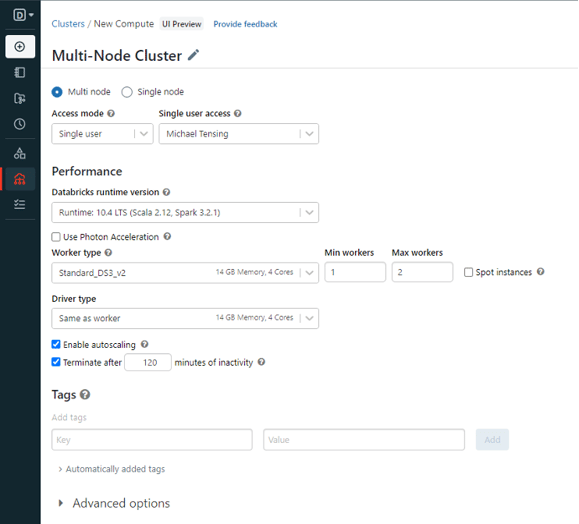
 Daar zie je het instelscherm voor het aanmaken van een cluster, dat vrij eenvoudig is. Het cluster is standaards ingesteld als een ‘Multi node cluster’, dat zoals de naam al aangeeft meerdere knooppunten parallel gebruikt. Dit is handig om te gebruiken bij zeer grote hoeveelheden data.
Daar zie je het instelscherm voor het aanmaken van een cluster, dat vrij eenvoudig is. Het cluster is standaards ingesteld als een ‘Multi node cluster’, dat zoals de naam al aangeeft meerdere knooppunten parallel gebruikt. Dit is handig om te gebruiken bij zeer grote hoeveelheden data.
Voor ons voorbeeld gebruiken we meestal de standaardinstellingen. Het enige wat je misschien wilt veranderen (in verband met de beschikbaarheid van rekenkracht binnen je organisatie) is het minimum en maximum aantal benodigde werknemers.
Het gebruik van het Standard_DS3_v2 Worker type met minimaal 1 werknemer en maximaal 2 werknemers zou voldoende geheugen moeten geven tijdens ons voorbeeld.
Dat is het! Je bent nu klaar om Python Notebook in Databricks te draaien.
Upload je Jupyter Notebook
Nu is het tijd om ons Jupyter Notebook, het .ipynb bestand, te laden. Klik op het tabblad ‘New’ en maak een nieuw notebook aan, waarna je op het tabblad ‘File’ kunt klikken. Vanaf hier klik je op ‘Import Notebook’ en blader je naar het .ipynb bestand dat je in het vorige artikel hebt opgeslagen (of je kunt het bestand hier downloaden).
Mooi, je hebt het notebook in Databricks geüpload! De enige regel code die moet worden toegevoegd is onderstaande code. Omdat we werken aan een cluster in een Cloud, moeten we nog steeds de benodigde pakketten erop installeren. In ons geval snowflake.snowpark.python.
!pip install snowflake.snowpark.python
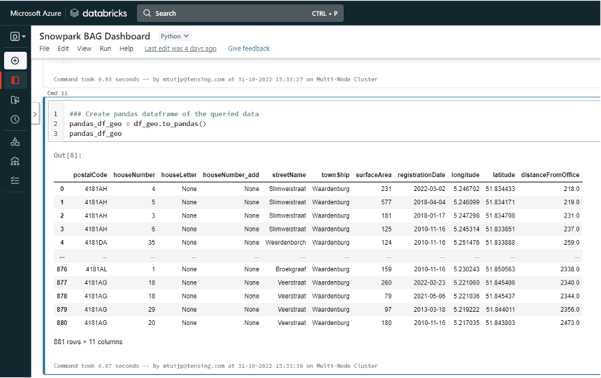
Nadat je die code hebt uitgevoerd, kun je de rest van de code op exact dezelfde manier uitvoeren als in Jupyter Notebook. Hiermee krijg je precies dezelfde resultaten.
Het opzetten van een notebook in Pipeline
Nu we dezelfde resultaten hebben geproduceerd als in ons Jupyter Notebook-voorbeeld, gaan we een stap verder. Omdat we onze notebook uitvoeren met Databricks, kunnen we enkele zeer eenvoudige tappen volgen om deze notebook periodiek in onze Cloud-omgeving uit te voeren zonder menselijke handelingen.
In de hoofdbalk aan de linkerkant ga je naar het onderste tabblad ‘Workflows’. Van daaruit klik je op ‘Create Job’, waarna je onderstaand scherm ziet. Hier vul je bij ‘Type’ in Notebook en bij ‘Source’ vul je Workspace in. Vervolgens selecteer je het pad naar je notebook en het cluster dat we zojuist hebben aangemaakt. Daarnaast kun je enkele geavanceerde opties gebriken om bijvoorbeeld te kiezen voor het sturen van een e-mail naar iemand in geval van falen.
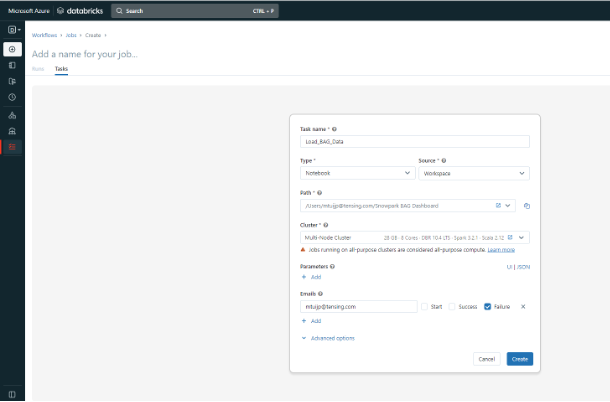
Nadat je de taak hebt ingesteld, kun je je notebook ook plannen om periodiek te draaien op een specifieke dag en tijd. Na het aanmaken klik je rechts op ‘Schedule’, wat je naar onderstaand scherm leidt. Hier stel je precies in wanneer en hoe vaak je het notebook wilt uitvoeren.
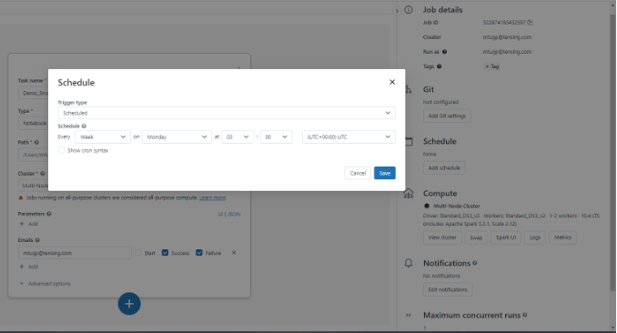
Gefeliciteerd! Je hebt niet alleen een notebook gemaakt binnen Databricks dat verbinding maakt met een openbare BAG-dataset in Snowflake, maar je hebt ook een automatische workflow opgezet om het notebook op specifieke tijdsintervallen uit te voeren. Wat vroeger nogal wat complexe handelingen vereiste, kostte nu slechts een paar klikken!
Wil je meer weten over mogelijke toepassingen als deze, neem dan contact met ons op. We helpen je graag!
