


.png)
Wat is Geospatial Data Science?

Michael Tuijp
Geospatial Data ScientistData Science is een buzzword. Het wordt gebruikt als synoniem voor (Big) Data Analyse, Machine Learning, Deep Learning en Artificial Intelligence. Ik merk dat er daardoor veel verwarring bestaat over wat Geospatial Data Science nu precies is (en wat het niet is). In een serie van drie blogs schep ik de komende weken helderheid over de terminologie en de mogelijkheden van dit fenomeen. In deze eerste blog begin ik bij het begin: wat is Geospatial Data Science?
De Geospatial Data Science lifecycle
Een Geospatial Data Science (GDS) proces kan je omschrijven in zeven stappen:
- Bepalen van het business doel;
- Data verzamelen (Data Engineering);
- Data opschonen (Data Engineering);
- Data verkennen (Data Analyse);
- Feature Engineering (Data Analyse);
- Predictive modelling (GDS/AI/ML/DL);
- Datavisualisatie.
Afbeelding 1: de zeven stappen van (Geospatial) Data Science. Tekst gaat verder onder de afbeelding.
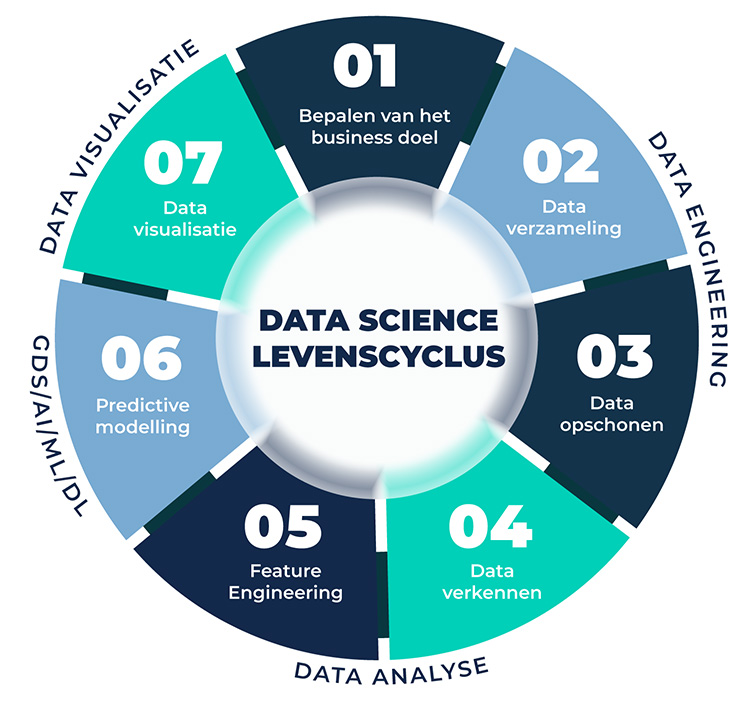
Stap 1: Bepalen van het business doel
De eerste stap is universeel voor ieder project dat met data te maken heeft. Bepaal het doel. Wat wil je weten en waarom? Geospatial Data Science bedrijven is geen doel op zich, maar een middel om datagedreven beslissingen te nemen.
Als Consultant is dit mijn grootste toegevoegde waarde voor klanten van Tensing. Alleen de technische kant beheersen volstaat niet. Als externe kracht kan ik met een open blik naar je organisatie en je doelen kijken. Ik kan je helpen om doelen en middelen goed te scheiden. Daarnaast is er heel vaak veel meer mogelijk dan je denkt.
Stappen 2 en 3: Data Engineering
Data Engineering is technisch gezien de eerste stap in alle datagerelateerde processen. Op zijn beurt bestaat het uit twee stappen. Stap één is het verzamelen van de benodigde data voor het specifieke project. Vaak komt er heel wat bij kijken om de juiste data te ontsluiten uit de juiste bronnen en in de juiste formats. Kijk daarom heel kritisch naar wat je nodig hebt en vooral wat je niet nodig hebt. Dit komt de efficiëntie later in het proces enorm ten goede.
Na het samenstellen van een geschikte dataset is het tijd om data op te schonen. In de praktijk ontbreken er altijd waarden, bestaan er verschillende tabellen die hetzelfde betekenen en is er vaak inconsistentie aanwezig.
Tensing gebruikt voornamelijk FME (een ETL-tool die geoptimaliseerd is om met geodata te werken) om de Data Engineering fase tot een goed einde te brengen. Als Geospatial Data Scientist kan ik daarbij vertrouwen op 60 gecertificeerde collega’s die volledig gespecialiseerd zijn in Geospatial Data Engineering.
Afbeelding 2: FME is wat Tensing betreft de beste softwarekeuze op gebied van Geospatial Data Engineering. Tekst gaat verder onder de afbeelding.

Stappen 4 en 5: Data Analyse
Na de afronding van de Data Engineering-fase is het tijd om met de data te gaan werken. Op basis van hypotheses test je of je alle gewenste inzichten uit de beschikbare dataset kunt halen. Dit doe je met behulp van testvisualisaties. Wanneer je vaststelt dat je dataselectie volledig is, ga je verder. Soms komt het voor dat je Data Engineering-stappen nog wat finetuning nodig hebben voor je verder gaat.
Tijdens de Feature Engineering-stap maak je nieuwe features aan op basis van bestaande data. Het gaat hierbij om waarden die relevant zijn voor je model, maar die niet als aparte variabele zijn opgenomen. Ik neem brutowinst als voorbeeld: omzet – inkoopwaarde. Als je winst als aparte feature nodig hebt om je voorspellende model te genereren, neem je deze tijdens de Feature Engineering-fase op in je dataset.
Het zorgvuldig doorlopen van de eerste vijf stappen is essentieel voor je aan de predictive modelling- fase begint. Ten eerste omdat je met grote lijsten errors geconfronteerd wordt. Ten tweede omdat het resultaat onder de noemer garbage in, garbage out zal vallen. De inzichten die uit je model komen vertonen waarschijnlijk extreme uitschieters, zijn mogelijk veel te positief (of negatief), of ze zijn gewoon niet te rijmen met de realiteit.
Stap 6: Predictive modelling
Data Science wordt vooral geassocieerd met de predictive modelling-fase. Het voorspellen van trends op basis van gegevens uit het verleden (en het heden). Artificial Intelligence, Machine- en Deep Learning zijn middelen die predictive modelling mogelijk maken. In een volgende blog ga ik uitgebreid in op een praktisch voorbeeld: predictive maintenance. Dus houd onze social kanalen en website in de gaten!
Predictive modelling is onmogelijk zonder het zorgvuldig doorlopen van de voorgaande stappen. Data heeft alleen waarde als het 100% correct is. Dat gegeven is een absolute waarheid als je Data Science bedrijft.
Stap 7: Datavisualisatie
Datavisualisatie is waar je het (meestal) allemaal voor doet. Om bepaalde inzichten aan verschillende stakeholders op een begrijpelijke wijze te vertonen is een dashboard, een heatmap of een 3D visualisatie, afhankelijk van wat het beste bij je project past, ideaal.
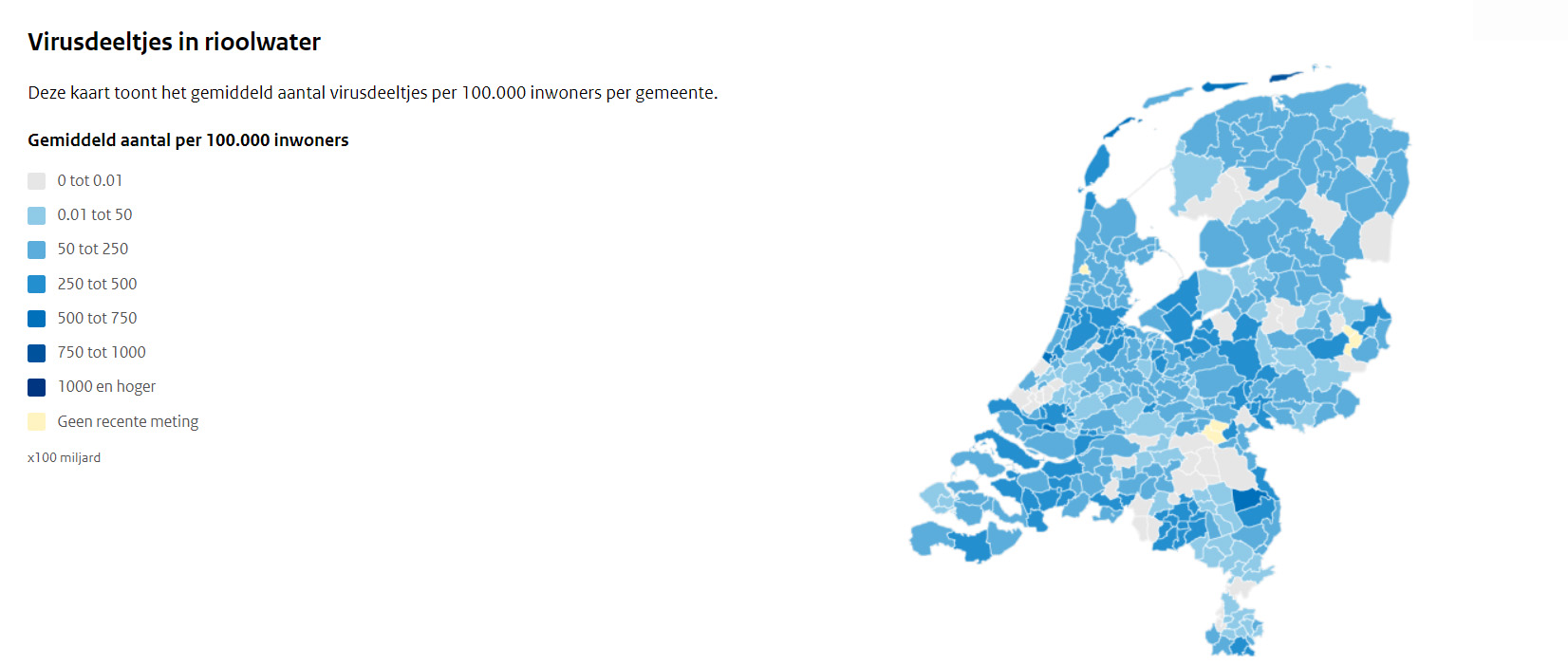
Afbeelding 3: één van de meest bekende dashboards van de afgelopen jaren. Tekst gaat verder onder de afbeelding.
Geospatial data science en Het geografische component
De wereld van geografische informatiesystemen heeft zijn eigen niche veroverd. Werken met locatiedata is toch nét even anders. Dit geldt ook voor Geospatial Data Science. Het goed integreren van databronnen zonder geografische component met geometrische gegevens is daarin de voornaamste uitdaging. Uitgebreide kennis van geografische data is absoluut noodzakelijk om voorspellende modellen te maken die je niet alleen kunnen vertellen wat er gaat gebeuren, maar ook wáár.
Hulp nodig bij een Geospatial Data Science uitdaging? Neem gerust contact op!